![Unsupervised Federated Learning for Speech Enhancement from non-IID Data [WASPAA 21]](https://i.ytimg.com/vi/nJ8knZGaUKg/hqdefault.jpg)
Unsupervised Federated Learning for Speech Enhancement from non-IID Data [WASPAA 21]
Published at : September 26, 2021
Video presentation for the paper:
Efthymios Tzinis, Jonah Casebeer, Zhepei Wang and Paris Smaragdis, "Separate but Together: Unsupervised Federated Learning for Speech Enhancement from non-IID Data." In IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), 2021.
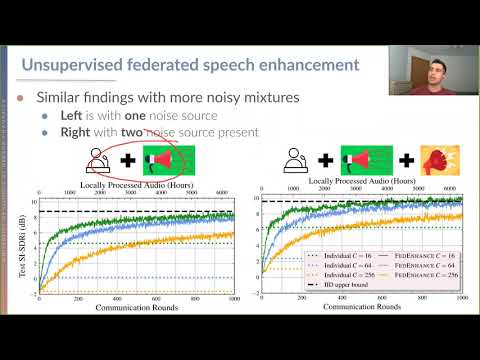
We propose FEDENHANCE, an unsupervised federated learning (FL) approach for speech enhancement and separation with nonIID distributed data across multiple clients. We simulate a realworld scenario where each client only has access to a few noisy recordings from a limited and disjoint number of speakers (hence non-IID). Each client trains their model in isolation using mixture invariant training while periodically providing updates to a central server. Our experiments show that our approach achieves competitive enhancement performance compared to IID training on a single device and that we can further facilitate the convergence speed and the overall performance using transfer learning on the server-side. Moreover, we show that we can effectively combine updates from clients trained locally with supervised and unsupervised losses. We also release a new dataset LibriFSD50K and its creation recipe in order to facilitate FL research for source separation problems.
arxiv: https://arxiv.org/pdf/2105.04727.pdf
github: https://github.com/etzinis/fedenhance
Efthymios Tzinis, Jonah Casebeer, Zhepei Wang and Paris Smaragdis, "Separate but Together: Unsupervised Federated Learning for Speech Enhancement from non-IID Data." In IEEE Workshop on Applications of Signal Processing to Audio and Acoustics (WASPAA), 2021.
We propose FEDENHANCE, an unsupervised federated learning (FL) approach for speech enhancement and separation with nonIID distributed data across multiple clients. We simulate a realworld scenario where each client only has access to a few noisy recordings from a limited and disjoint number of speakers (hence non-IID). Each client trains their model in isolation using mixture invariant training while periodically providing updates to a central server. Our experiments show that our approach achieves competitive enhancement performance compared to IID training on a single device and that we can further facilitate the convergence speed and the overall performance using transfer learning on the server-side. Moreover, we show that we can effectively combine updates from clients trained locally with supervised and unsupervised losses. We also release a new dataset LibriFSD50K and its creation recipe in order to facilitate FL research for source separation problems.
arxiv: https://arxiv.org/pdf/2105.04727.pdf
github: https://github.com/etzinis/fedenhance
UnsupervisedFederatedLearning

Instant Ksol Token Withdraw Airdop Legit Airdop Claim

Even When It Look Like Politicians Are Losing They Still Win.....

Describing Food and Drink in Chinese

Women Are Stronger Than Men LOL - MGTOW

Sorry guys I have been really busy and it is because im going back to school tomorrow

Just In: Kenedy Agyapong In Serious Trouble As Ahmed Suale's wife Told To also Súe Him For Dàmages.

How to Minimize Risk in Newer Crypto Assets for Beginners

Shang Chi Alternate Ending and Post Credit Scene Deleted Scenes Breakdown - Marvel Phase 4

How many mat do you have #shorts #bathroom #lifewit

r/TerminallyStupid - ah yes, ”Science”

George and Peppa Get Sick! 🐷🤒 @Peppa Pig - Official Channel

😱 நண்பன் படத்தில் சொன்னது உண்மையா? 😳 _ Tamil Facts _ Fact Force #shorts

Peyton & Eli are Genuinely Confused

FORMER RUTO ALLIE ASMAN KAMAMA FINISHES RUTO AS HE OPENLY DITCHES HIM FOR RAILA

Most Americans Concerned About Economy, Inflation, Polling Shows

‘Stuff it, shove it’: a furious Michael Gunner blasts those against vaccine mandates

My PROBLEM With Re: Zero's Story.

The Best SMG in Vanguard? | MP 40 Stats & Best Attachments (Gun Guide #3)

Crypter - Social Network Platform For Crypto Enthusiasts - Earn At Home - Download App Crypter
